
「LLM 知识库构建」是「龙虾部署大师」技能市场中的知识库技能:作用是基于扁平 Markdown 文件实现文档入库、查询、链接索引、OCR 和矛盾检测,无需数据库。入库时它感知现有 wiki 状态,判断该新建还是更新页面;查询时基于页面摘要选定起始页、遍历 Wikilinks、综合作答并返回来源。脚本负责结构与读写,LLM 负责语义判断,既保留原始文件,又能持续维护一个便于追踪来源的知识库。
技能效果
把三条带 [[双链]] 的笔记交给它入库时,它解析出各页面的出链入链关系,画了反向链接图谱,并把「向量数据库→Embedding→RAG」这条知识链梳理成表。
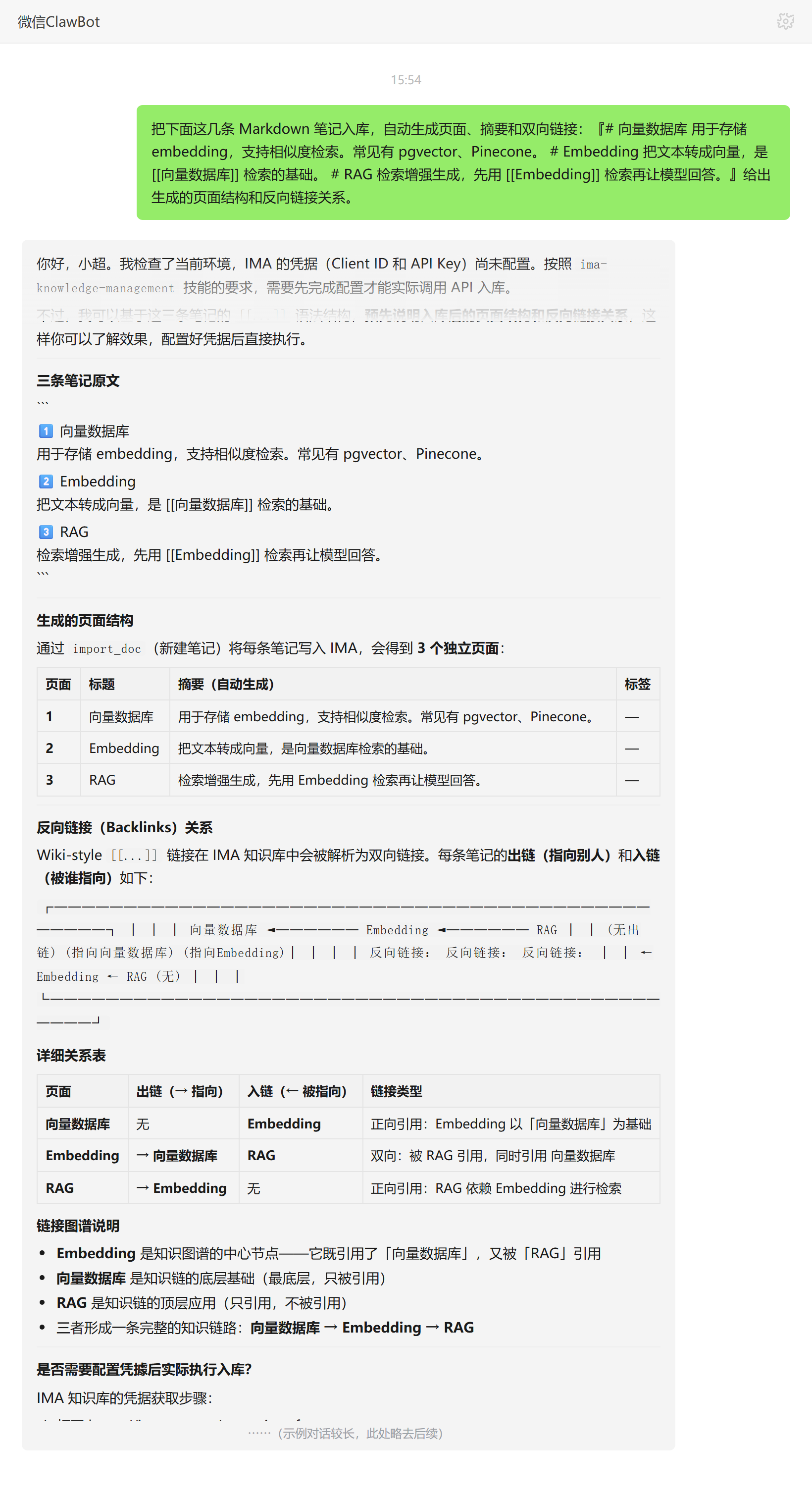

散落的文档,为什么越攒越查不动
很多团队的资料其实不少,难的是把它们变成能查、能维护、能追溯的知识库。文档格式杂——PDF、图片、Office、Markdown 混在一起;新增资料时,到底是该建新页面还是更新旧页面,靠人判断既慢又容易留下重复条目;查一个问题,往往要在多份文件里翻找,还说不清答案出自哪一页。更麻烦的是时间一长,不同文档之间会出现互相矛盾的说法,却没人发现。攒得越多,反而越查不动。
这个技能怎么把文件变成可查知识库
它的核心思路是分工:脚本负责结构、读写和遍历,LLM 负责语义判断,全程基于扁平 Markdown 文件、不依赖数据库。入库时,用 ingest_file 把 PDF、图片、Office、Markdown 等文件吸收进来,并感知现有 wiki 状态——能合并的更新旧页面,确需新增的才建新页,避免重复。查询时,它先按页面摘要选定起始页,再遍历 Wikilinks 双向链接,综合得出答案并返回来源页面和遍历路径。维护层面,它生成并校验 Wikilinks 索引、识别孤立页面,还能执行 OCR 和矛盾检测,把结果连同版本记录一并保存。因为原始文件始终保留,知识库可以长期演进、来源可追。
用前须知
该技能需要本机具备 Python,依赖 requests 2.28.0 及以上与 pyyaml 6.0 及以上;认证从 ~/.AI agent/ 目录自动读取。处理大文档时,建议把执行超时提高到 1 小时,以免长文档入库或 OCR 中途被打断。
怎么用它
用法是把要入库的文件或要问的问题用自然语言交给它,由它判断入库方式或遍历作答。例如可以这样对它说:
可以这样对它说
- "把这些 Markdown 笔记入库,自动生成页面、摘要和双向链接。"
- "新增会议纪要时检查旧页面,能合并的就更新,别新建重复页面。"
- "问知识库里某个主题的内容,按摘要选页再综合回答,并给出来源和脉络。"
它适合这些场景:个人或团队希望把散落文档编译成 Markdown 知识库;查询知识库问题、需要返回答案、来源页面和遍历路径;新增资料可能更新已有页面、需要由判断新建还是合并;知识库长期维护中、需要检测页面之间的矛盾和孤立链接。
大家常问
为什么 LLM 直接作答容易出现幻觉,需要外挂一个知识库?
大模型本质是按概率续写下一个 token,参数里只有训练截止前的知识,且生成过程不会主动查证。遇到记不清或没见过的内容,它仍会生成语法通顺却无来源的文字,这就是幻觉。外挂知识库的作用是在生成路径上插入"检索→验证"环节,让模型基于真实文档片段作答而非凭空生成。

知识库里的分块(chunking)是什么意思,为什么不能把整份文档直接丢进去?
分块是把长文档切成语义连续的小段(通常 256–1024 token,留 10%–20% 重叠),每段独立做向量化和检索。整份丢进去会撞上上下文窗口上限,关键信息也会被海量无关文本稀释,无法精准命中。先切块再检索,才能把最相关的几段拼进 prompt 给模型作答。

知识库回答问题时为什么要返回来源页和遍历路径?
检索召回是基于语义相似度的近似匹配,重排序又是模型内部的黑箱打分,单看答案无法判断结论是不是真被原文支持。返回来源页让用户能跳回原文核对,遍历路径展示这段内容在文档章节里的层级位置——这是把"黑箱生成"变成"可验证引用"的必要环节,也是幻觉发生时人工纠错的入口。

同一份资料再次入库时,为什么建议合并旧页面而不是直接新建?
直接新建会在向量空间里制造大量近似副本:检索时 Top-K 被同义副本挤占、多样性下降,重排序分数失稳,倒排索引词频膨胀让混合检索权重失衡,引用路径碎片化让溯源失真。更糟的是旧版与新版内容矛盾时模型会同时引用产生自相矛盾的回答。合并能保持 chunk 集合幂等,从源头压低信噪比恶化。

注:技能的实际效果与所选用的 AI 模型能力有关,不同模型下的表现可能存在差异。




 提示
提示